BCI and AI applications in Epilepsy care, intracranial EEG (icEEG), and Neurology
Table of Contents
This commentary is about our article:
Brain-Computer Interface (BCI) Applications in Mapping of Epileptic Brain Networks Based on Intracranial-EEG: An Update
Introduction
History of relevant statistics
Statistical analysis studies the various aspects of data collection and helps us decide when we need to know how accurate something is. Statista, from the Latin statum collegium, became statistics in the early 19th century. Empires often collected data on their geographical area and population during civilization. In the 5th century BCE, the Athenians used statistical methods for the first time. They used a technique called the Athenians' calculation to determine the height of the walls. The word algorithm comes from Abu Bakr al-Khwarizmi's last name. From the title of his book, Ilm al-jabr wa l-muqābala comes to the word Algebra, which set the foundation, in the 10th century, for modern mathematics and computer science.
In the 16th century, the arithmetic mean was expanded to two decimals. Grant and Petty's work in 1662, known as the first modern census, led to the maturation of modern statistical methods.
I have become fascinated with statistics since learning that you can predict how likely it is to hit more than 50 sixes on random 100 rolls of a dice. This is impossible without math. At first glance, the odds appear reasonable. Mathematics, however, indicates that the probability is less than one in 10^10.
Bayesian statistics and regression
Gauss and Legendre introduced the least-squares method in 1805-1809. Both men discussed determining the orbits of bodies in space, such as the sun. The term "regression" was coined in the 19th century by Francis Galton to describe a biological process whereby the height of an ancestor of a specific size falls to an average size. Pearson and Yule assume that the distributions of the response and explanatory variables are Gaussian.
According to Bayesian interpretation, probability is an expression of belief about an event. The degree of confidence may be derived from prior knowledge of the event or personal opinions. The Bayesian theorem is a statistical method for computing probabilities after an event. It can also be used to estimate the parameters of a statistical model. Probability is a degree of belief in Bayesian statistics, so its distributions can be assigned to parameters. Thomas Bayes introduced the statistical procedure in 1763. In the decades that followed, several papers were published on statistical problems. Later authors developed many techniques and methods not commonly used until the 1950s. Today's researchers can study and apply Bayesian methods using modern algorithms and powerful computers.
In a nutshell, regression is used to predict based on observed data, whereas Bayesian statistics explore inherent probabilistic qualities.

Example: Imagine the height values regressed against age; in linear regression, the goal is to predict height based on age. Logistical regression predicts two classes, tall and short, based on age. Regression may exploit complex functions besides linear relationships.
Artificial Intelligence (AI)
History of AI
In the preceding centuries, computation efforts culminated in devices based on a complex mechanical design to execute the Fourier transform. The dynamics of World War II probably sparked the concept of AI and machine learning. The Enigma and Bombe machines were among the first examples of machine learning. In 1951, Ferranti Mark 1 became the first machine to successfully execute an algorithm to master checkers. During the 1960s, researchers worked on algorithms to solve math problems. The following decades saw the development of machine learning for robots.

AI Components
What is AI?
Artificial intelligence is a field of computer science that uses programming and computational methods to create intelligent machines. The area was founded in 1956 by John McCarthy, who coined the term "artificial intelligence" to refer to his theory of "general and adaptive" intelligence. Artificial intelligence research is highly technical and relies on many fields, including computer science, mathematics, psychology, neuroscience, linguistics, philosophy, and engineering.
To put it simply, let's imagine that:
We take the regression from 2-D to N-D universes with N features. Boundaries are no longer linear and can take on any mathematical function or kernels. Through iterations and cross-validation, or prospective implementation, rules, and misclassification costs, it is possible to maximize classification success rather than focusing on mathematical perfection. Thus, the algorithms could learn from their own mistakes. Algorithms could be modified to enhance the classification of rare occurrences/phenomena via assigned weights to the training data.
Consider all of the possible combinations of features and processing and decide which variation is appropriate, or a trained expert may develop a multistep decision tree based on regression, simple logic, xor, or Tanh functions, advanced processing, and (logistical) regression(s), or simply expertise. Imagine different combinations and possibilities. In essence, this is what machine learning is all about. Simply put, it is mathematical functions on steroids.
Key concepts:
Traditionally, machine learning algorithms are constructed by taking samples of the entire population to represent it. The data set is typically divided into two or more datasets training and validation. In general, the machine learning portion of the dataset is used for construction, whereas the rest is used for evaluation. The data in this set is often unbalanced; it is based on tiny sample size. Because machine learners are imbalanced, they struggle with fraud detection, network intrusion, and rare disease diagnosis. It is possible that these unusual situations, which were unnoticed during the training phase, could be misclassified during the testing phase if the proper adjustments are not made. It is possible to compensate for that by weighing and introducing dummy variables.
Problems (classification, prediction, detection) The challenge of classification in machine learning is correctly assigning a class to an instance. As an example, with a set of images of animals, the classification problem is to determine which image is of a dog and which is of a cat. Like many other areas of medicine and life, this problem is often binary, categorized as epileptogenic zone (EZ) or non-EZ, for instance, in surgical epilepsy. Machine learning can be used for predictive modeling, which uses past data to predict future events. The goal is to identify patterns in the data that can predict future outcomes. These outcomes could be an assigned value such as height, age, or binary. One of the main applications for machine learning is in the area of detection. This involves identifying patterns in data that can be used to identify instances of something being looked for, such as cancer cells in a biopsy or fraudulent activity on a credit card. In many cases, the goal is to identify these instances as early as possible to be treated or stopped before they cause damage.
Supervised vs. non-supervised Machine learning can be supervised or unsupervised. The algorithm is trained with labeled data in supervised learning to build a model for classifying new examples. In other words, patterns are sought to predict the following user experience. Non-supervised learning does not exhibit this type of pattern recognition; instead, it detects hidden structures in unlabeled data that may be useful for future predictions or decisions. For example, in the case of the alphabet, it will identify familiar patterns. In the case of intracranial EEG could very well reveal insights and clusters unintelligible to an intelligent eye.
Supervised Learning Example: We want our machine learners to learn how to categorize pictures of cats and dogs. When you show an image without telling it anything, it knows whether there's a cat or dog in the photo based on its training set.
Training, reinforcing, and implementation Training teach a computer how to learn from data. It involves feeding the computer a large set of data and telling it what each example in the data set represents. For example, you might train a computer to recognize pictures of cats by feeding it an extensive collection of photos labeled "cat" and "not cat." The computer will then be able to look at an unlabeled picture and correctly identify whether there's a cat in it or not. Reinforcement learning is a type of machine learning where the computer learns by trying things and being rewarded or punished for its actions. For example, a computer might learn how to play a game by trying different moves and being rewarded when it wins or punished when it loses. Implementation in machine learning refers to the actual process of putting a machine learning model into practice. Once a model has been trained, it needs to be implemented for real-world applications. This might involve building a website or app that uses the model or integrating the model into a more extensive system.
Deep learning is a more sophisticated type of machine learning. This artificial intelligence technique mimics how the human brain analyzes information and produces patterns for decision-making by simulating how the human brain works. The learning procedure involved in machine learning is carried out by a hierarchical level of artificial neural networks. The artificial neural networks are constructed like the human brain, with neuron nodes linked like a weblike network. Typically, deep learning is applied to raw data, and the insights obtained are unique. This is a form of computational research. Deep learning successfully beats the human world champion in the game of go. For diagnosis of some specific diseases, it has matched the level of medium or senior professional physicians. Deep learning is like learning from your mistakes very quickly, like at the speed of electrical circuits.
Resources a quick review of this Wikipedia article on the category of machine learning algorithms confirms perhaps is one of the naïve mistakes is to obsess about an algorithm rather than the clinical question on hand. The size of data, the number of features to be extracted, and whether it is supported by data size, data cleaning, and pre-processing are essential—plan for validation and cross-validation and online reinforcement of the model. For instance, in the epilepsy world, I often find that variability in performance between two popular machine algorithms, such as support vector machine and random forest, is pretty much marginal compared to known, accepted differences between human readers, say whether in spike detection or seizure onset classifications.
In my laboratory AI configuration, I used Matlab(R). I built a custom-made amplifier for my BCI system to interface with Matlab. Some individuals may utilize low-level machine code created by 3rd party device manufacturers with their SDK. It's not only the most popular in the industry; it's also the most appealing to design the whole widgets, with software tailored for hardware and vice versa. In this case, both doctors and patients have reported that this provided them with the best customer experience.
There are many different other packages, including 100% open source choices:
Python and related libraries NumPy, Pandas, Matplotlib, Sickit-Learn, TensorFlow, Keras.
Some recommended reads: Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems 2nd Edition, many many other related resources on O'Reilly library
Some recommended courses: Google AI; this Coursera course has been suggested.
A word about the historical lag Some popular algorithms have existed since the 60s of the past century. It lagged simply because computers of the time were not powerful enough to carry on complex tasks such as voice recognition. Nowadays, it feels as if the sky is the limit.
“Robots will be able to do everything better than us,” Musk said during a speech. “I have exposure to the most cutting edge AI, and I think people should be concerned by it.”
Popular Algorithms
We'll go through six of the most popular machine learning techniques, covering their design and applications. Keep in mind that there are various types of machine learning networks to consider. New varieties are being developed all the time. It's been claimed that if you randomly arrange three letters, you'll end up with the name of a current deep learning algorithm.
Support vector machine (SVM)
Perhaps the most popular for binary classification. That is to distinguish two states: epileptic brain or seizure onset zone vs. non-epileptic brain, resectable and non-resectable, etc. The support vector machine (SVM) is a supervised machine learning technique regarded as one of the most robust and precise classifiers. It discovers a decision boundary that provides the best margin between the closest training data of different classes.
The decision boundaries of SVMs may be linear or nonlinear, depending on the distribution of training examples. In many real-world situations, features are not linearly separable. A nonlinear decision boundary or hyperplane may be constructed with little additional computing work by employing a range of kernels (e.g., curved line, cluster rather than a multi-dimensional line). The following are the most common kernel functions: linear, polynomial, radial basis, and sigmoid function (Vapnik, 1999). Think of SVM of multi-variate regression(s) on steroids with many customizations for training and implementation.

IN SVM, think of this concept extended to N dimensions and that the separator of a line/plain is just an option of many other functions (Kernels).
Multilayer Network or Perceptron (MLP)
A multilayer perceptron is a structure that consists of input, hidden layers, and output. The outputs of the hidden layers are computed as a function of the sum of weighted intermediate parts, hence the similarity to human brain neurons and decisions.
These functions could be a combination of the effect of Tanh, binary, linear, exponential, logarithmic, or sigmoidal functions on the multiple neurons. A feed-forward neural network is used to output outputs from inputs. It is commonly referred to as a multilayer perceptron. The complexity of the problem it can solve makes it an ideal tool for studying machine translation and neuroscience.
The main disadvantage of a multilayer perceptron is its high number of total parameters. Since it has redundant factors, it can be inefficient. Deep Neural Networks are systems designed to handle large amounts of data. They use sophisticated mathematics to simulate the activities of the human brain and multiple intermediate decisions. Deep learning is a type of computer programming that learns how to classify and collect different data types.
Furthermore, it can learn how to sort and order the data collected not necessarily through supervision but rather through inherent similarities. They commonly use deep learning to sort and organize unlabeled data. For instance, it could also classify video data by performing multi-state graph analysis. A multi-state graph is still not as powerful as a convolutional neural network (CNN) when processing real-world data despite its advanced capabilities. A CNN, the current champion in computer vision algorithms, learns and identifies patterns in an image regardless of its origin.

Three popular activation functions at the level computational synapse, or node.
In 1958, Frank Rosenblatt of Cornell Aeronautical Laboratory developed the perceptron algorithm. It was a device that could recognize images using a random array of photocells. The concept of perceptrons was that they could control and walk autonomously. However, they were not very effective, then at handling many patterns. The development of perceptrons took many decades to recover, given the limitations of the times.

Two neural networks. The one on the right is a deep learning network.
K-nearest neighbors (k NN)
It involves determining the distance of a test sample to the nearest known pieces and arranging similar patterns in space. The term k-means has been used since 1967, though the idea of using k-means to describe a simple algorithm dates back to 1956 by Hugo Steinhaus. In 1957, Stuart Lloyd of Bell Labs presented a method for pulse-code modulation.
Random Forest
It is a relatively new, highly efficient algorithm that uses increasingly computational memory. Michael Breiman created it in 2001. This supervised learning algorithm does not require hyperparameter adjustment. Hierarchical classification is based on multiple decision tree models.
Random forests use the regressor of the algorithm instead of combining it with other features, like decision trees. This technique adds more uncertainty to the model and may reveal the most significant pattern among the random features through many integrated iterations. The algorithm outperforms other binary classifiers, but modeling connections is more computationally intensive. Mathematically, it is pretty simple to implement; decision trees could also be visualized. Furthermore, it can outperform neural networks and expert-driven preconception planning.

Illustration of random forests and random weighting of features in every tree. This maximizes the chance of successful classification.
Decision Tree
A decision tree is a supervised machine learning algorithm used for classification and regression problems. A decision tree is simply a series of sequential decisions made to reach a specific result. Think of planning your program or algorithm before translating that into code.
Logistical regression
Logistical regression is a type of regression analysis used to predict the outcome of a categorical variable. It is used when the dependent variable has more than two levels. In other words, it is used when you want to predict a particular category or outcome from a set of data. The data is first divided into training and test data groups. The training data is used to create the model, while the test data is used to evaluate the model's accuracy.

Logistical regression sigmoid function and deceision boundary.

Linear regression decision boundaries
There is always the option to bypass existing algorithms and develop their new metric. In our case of mapping the central sulcus passively during sleep from free-running EEG data, we performed a supervised design rather than learning compared to existing machine learning techniques. The study can be found here.
Brain-Computer Interface (BCI)
What is BCI?
The brain-computer interface (BCI) is a device that interprets brain activity into a message or computational command. BCIs provide a more detailed picture of the brain's activity, which can help develop prosthetic devices and options to treat epilepsy that is resistant to drugs. BCI applications are becoming more relevant as the amount of information encoded in brain electrical activity increases.
The components of a BCI
The BCI consists of sensors, interpreters, and real-time processing of an EEG signal, typically and most realistically to match the complexity of the brain and speed of computers. Whole integrated widgets where software and hardware are developed parallel remain the most popular for the best end-user experience. There are many options for academic and industrial projects that commonly use EEG amplifiers designed to work seamlessly with multiple middle-level languages, more accessible for many to handle by many researchers.
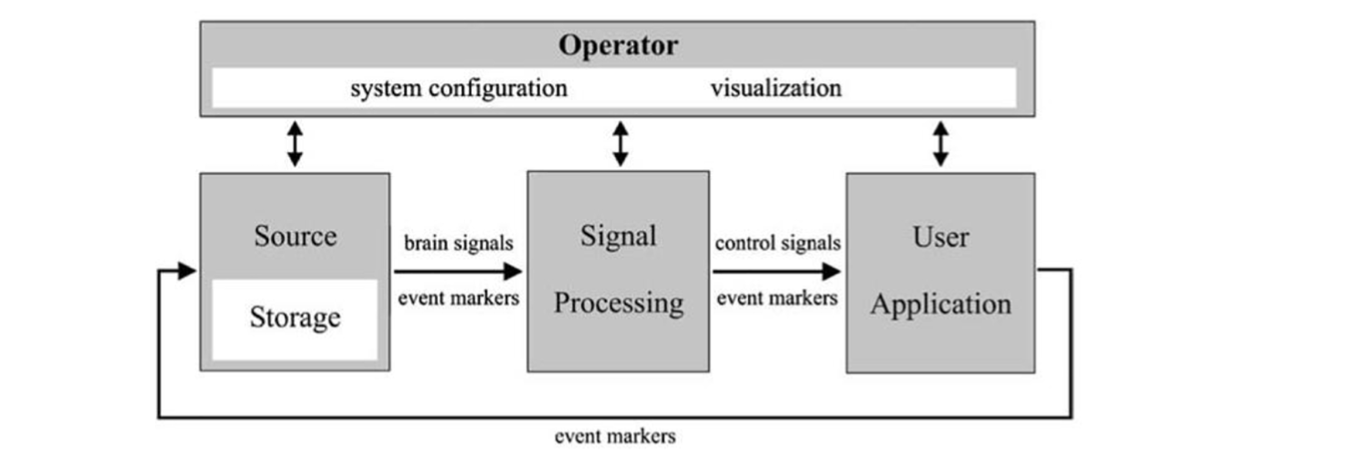
A schematic showing a universal design for BCI systems. It is adapted from BCI2000 IEEE.
Examples of current day BCI
AI can produce insights momentarily from a large amount of intracranial EEG data. This sets the stage for BCI to shine in the settings. Current day examples: In Epilepsy: Responsive NeuroStimulation (RNS) or Neuropace (R), where a whole widget implanted in the brain can detect seizures and deliver currents all within a few seconds. We frequently employed real-time signal analysis in “Gamma-mapping” to identify the areas in the brain responsible for language processing and sensory-motor functions. The standard procedure may take days to complete. AI/BCI can enable comprehensive results in under 30 minutes.
Outside the epilepsy world, consider this Twitter announcement as a form of futuristic BCI application. The field of prosthetic control is a life-changing experience for those affected with quadriplegia or other ischemic events, or other neurological degenerative disorders. Consider this work, for instance, among many other applications.

An experiment like the one shown, in which the prosthetic matches the individual hand position as interpreted from EEG data, can be set up quickly with hobbyist-level equipment.
Epilepsy Landscape
Epilepsy is a central nervous system disorder characterized by hyperactivity and an imbalance between excitation and inhibition. The brain balances routine activities such as reaching for an object or speaking. These are healthy inhibitory mechanisms (e.g., cerebellum, basal ganglia, negative motor areas, and pre-SMA). If these mechanisms are damaged, seizures may result significantly if the abortive seizure mechanism is impaired. Status epilepticus can result and is considered a medical emergency. Epileptic seizures resemble electrical storms, sometimes hurricanes. They may start in one region of the brain, spread, or originate from the entire brain at once.
Epileptic seizures: Prevalence
According to the Centers for Disease Control and Prevention, 1.2% of the US population had epilepsy in 2015. The United States has about 3.4 million epilepsy patients: 3 million adults and 470,000 children. 0.6% of children aged 0-17 have active epilepsy.
Additionally, data suggest that the lifetime risk of experiencing a seizure is approximately 4% or about one in 25 people. Epilepsy does not affect everyone who has a single attack. Epilepsy has many causes, such as congenital, cortical dysplasia, strokes, etc. However, one common denominator exists almost overlapping electroclinical syndromes that seem more anatomical than pathological, such as temporal lobe vs. extra-temporal lobe epilepsy.
Drug resistance and management
Antiepileptic drugs do not always control epileptic seizures. The cause could be an underlying disease process in the human brain or a poor response to therapy. Resistance appears to be a more common disease trait than our failure to develop a miracle cure. One-third of cases become drug-resistant, so widespread that new medications are benchmarked for seizure reduction rather than complete seizure freedom. Some refer to the condition as refractory epilepsy.
More than 20 drugs are available to treat seizure disorders, but only a third work in all cases. A combination of medicines will be tried before deciding if someone has drug-resistant epilepsy. An intracranial EEG evaluation, which gives unprecedented time and spatial resolutions of up to milliseconds and millimeters, is sometimes needed to determine the seizure focus and the part of the brain that requires surgery. See figure below. icEEG was superior to non-invasive scalp EEGs and other modalities when it indicated:
Common Indication of icEEG: Discordant non-invasive pre-surgical workup, MRI-negative neocortical epilepsy, and exceptional cases of mesial temporal epilepsy, MRI-lesional possibilities if Adjacent to the eloquent cortex, Explicit language or functional mapping is needed, Plan to maximally define the epileptic zone for completeness of resection such as in focal cortical dysplasia (FCD), Dual pathology or multifocality (i.e., tuberous sclerosis) If discordance with EEG data (i.e., scalp EEG is non-localizable). Current indications for backup Intra-Operative EEG recordings Select-cases in children, especially younger ones, Lesions with concordant non-invasive evaluations in focal cortical dysplasia, As an adjunct in multiple-subpial-transections (MSTs), Adjunct during intra-operative monitoring and mapping of eloquent cortex, As an adjunct in the Responsive Neuro-Stimulation (RNS) electrodes placement.
Evaluation of the intracranial EEG is not indicated in generalized seizures disorder or cases where it is clear that the seizures are multifocal and that surgical intervention is unlikely or a high-risk procedure.
Potential intracranial EEG markers
Risks of drug resistance include unexpected deaths, physical injuries, loss of quality of life, and many restrictions. Interventions are also not perfectly safe: Intracranial EEG and resection are significant surgeries. Currently, intracranial EEG is used to record seizures. Direct exposure to the brain may take days or weeks.

image of subdural electrodes in pre-resection evaluation
Thus, any steps towards shortening and standardizing the process are welcome and badly needed, especially in this age of computation and technology advances.
Possible emerging markers:
Epileptiform Discharges Interictal EEG spikes are commonly associated with epilepsy. They can also be seen in tissues and regions far from epileptic areas. Points tend to be most prominent in the vicinity of a seizure onset rather than from within. Studies have suggested that seizure onset is associated with the co-occurrence of spikes and overriding high-frequency oscillations. Spike-HFO detectors can be fine-tuned to improve their efficiency, according to this finding.
Intraoperative Spike Monitoring Controlled trials are needed to determine the best use of this procedure. Spikes in the final post-ECOG may predict poor surgical outcomes, but the evidence is conflicting. Although spike-HFOs may provide a more reliable marker for epilepsy, they are not suitable for clinical use. There is no consensus on the best anesthesia regimen for intraoperative monitoring. The gold standard for localization does not support the concept of spike activation.
High-Frequency Oscillations (HFOs) and Very High-Frequency Oscillations (VHFOs) – See the Previous Section. Interictal high-frequency oscillations (HFOs) have been studied for the localization of epileptic foci. Nevertheless, their utility is not yet straightforward. Interictal HFOs are helpful, but they do not meet current standards. In tertiary centers, clinicians deal with complex cases spanning anywhere in the neocortex, whereas very high frequencies tend to be more specific; they are localized to mesial temporal epilepsies.

Demonstration of the spatial distribution of physiologic high-frequency oscillations. A reliable classifier to distinguish those from epileptic ones is desired.

To date, no single EEG feature can reliably distinguish epileptic from non-epileptic HFOs.
A very high-frequency oscillation (VHFO) is a signal specific to a particular area or group of neurons. In-phase and out-of-phase action potentials of individual neurons can produce it. Basket inhibitory cells also play a role. The frequency ranges from 500 to 2000 Hz. VHFOs can be generated by removing the noise from alternating current cycles. Others are made by taking the average signal from all signals and applying it to the white matter. Yale's spatial sampling has led us to detect ripples and fast ripples outside the epileptic network consistently.
Brain Connectivity Functional connectivity studies the temporal connections between different neurophysiological events. The calculation can be performed in phases or amplitudes, and it can be bivariate or multivariate. The EEG's temporal resolution provides a unique method for assessing the different connectivity components. The Pearson correlation coefficient measures the coherence and correlation between two-time series. The most commonly used measures are the phase-locking value and the phase-lag index. Other measures include mutual information and transfer entropy. The concept of Granger causality is that if the past values of the first time series are included in the calculation of the second time series, the variance of the modeling error is reduced. Different measures can be derived from an autoregression model, such as the directed coherence index, the directed transfer function, and the partial directed coherence. Studies have shown that the inter-ictal phase of patients with epilepsy shows an increase in synchronization within the seizure onset area. A high-frequency Granger causality measure was also associated with contacts at seizure onset.
The Connectivity Index (CI) as New Measure to Grade Epileptogenicity Based on Single-Pulse Electrical Stimulation (SPES) Using faradic electrical stimulation, Victor Horsley confirmed the localization of a patient with epileptic focus. This procedure was performed in 1886 on John Hugh Jacksons’ patient. Studies on electrical stimulation are challenging due to the complexity of controlling for various covariates. A school believes high-frequency stimulation can be specific if correlated with chronic electro-clinical syndrome. We have shown that a new connectivity index metric can identify epileptic tissue even in extra-temporal epilepsy. This measure accentuates the value of responses that were recorded at distant sites. Our results indicated that the epileptic contacts generated higher response rates than the control sites. The evoked responses were also more robust when the distance between the stimulation site and the epileptic contacts connections was normalized.
The Epileptogenicity Index (EI) and Other Seizure-Related Metrics Clinical practices increasingly use quantitative seizure analysis. Evidence also suggests a link between the frequency of seizures and the duration of epilepsy and epileptogenicity in non-SOZ contacts. Additionally, there is limited evidence that high-frequency activity phase-locked to lower frequencies during seizures could improve surgical outcomes.
Provoked Seizures and Seizure Detection Electrical stimulation has been used in craniotomies since the 1880s. Most studies show that seizures are not localized to a 50-Hz stimulus, despite commonly held belief. 27% of the patients in our study experienced partial seizures, while 35% of the contacts experienced attacks triggered by 1 Hz stimulation. The seizures were habitual. A total of none of the subjects experienced non-habitual episodes or generalized seizures. Neurologists are interested in auto-seizure detection. Seizure detection algorithms have a sensitivity level of 60% to >90% and a false detection rate of less than 1%.
Alternative to invasiveness
Artificial intelligence (AI) is increasingly used in epilepsy treatment, including its potential to predict seizures and utilize machine learning to manage drug resistance, detect intracranial EEG markers, and provide an alternative to invasive monitoring, such as improving non-invasive MEG localization. The intracranial EEG generates data at a rate of 43 books per second. This has yet to be tapped by AI, and it provides an excellent tool beyond the capabilities of any natural human ability.
A few examples include synthesis and interpretation of multimodality preoperative work in preparation for surgery, the guidance of surgically resected tissue, review of medical and genetic data during treatment evaluation, and identification of deep brain stimulation and neuromodulation targets in non-resective workups. In no way should this imply that discovering medication more effective or eliminating epilepsies through complementing genetic and pathological landscapes are not actual accomplishments.
Vision
Being a middle-career doctor, I'm increasingly convinced that AI should take over some time-consuming activities that could be better spent elsewhere while benefiting patients. It is unusual to find a perfect marker and therapy that can replace physicians in today's medical environment. Doctors navigate complex clinical variables to reach binary and sometimes multiple-choice decisions. Exactly what AI excels at is interpreting a slew of weak features, not possible otherwise in a 1:1 relationship. It is sometimes called medical art. In my opinion, AI can improve nearly every aspect of practice. Take, for example, least of all, war zones or underserved areas.
Conclusion: Concluding remarks BCI, AI & Epilepsy and beyond
Because AI is modality blind, it almost goes without saying that this progress fits into a broader landscape of AI integration of medical care at large; as AI increasingly enters the field of medicine, it is poised to play a transformative role in that system. In addition, it can advance medical knowledge, democratize expertise, automate drudgery within the system, and allocate scarce resources. In war and peace, each of these roles could profoundly affect patients not just in the United States but throughout the world. Time to plan and reflect on regulatory, ethical, and legal challenges that will undoubtedly arise as we move forward with this transformation.
The question is not if but when and how many generations it will take us to transform into the obvious next step. Since epilepsy was called "falling sickness," great strides had been made.
Human-machine hybrids are possible as we continue to evolve as a species. We can use technology to our advantage and become more intelligent, avoiding the negative impact of encoded evolutionary traits in a more compact globalized world.
Conflict of interest statement:
Neither the original study nor this commentary had a conflict of interest other than caring about our drug-resistant epilepsy patients.
Keywords: Epileptic seizures, brain-computer interfaces BCI, mesial temporal lobe epilepsy, EEG signal, electrical stimulation, seizure detection, brain-computer interface technology, intracranial EEG evaluation seizures, single-pulse electrical stimulation, chronic experimental focal epilepsy, low-frequency stimulation, epileptic brain networks, human brain mapping, seizure control, seizure freedom, stimulation parameters, brain signals, refractory epilepsy, neural tissue, spatial resolution, temporal resolutions, Hertz, Milliseconds, habitual partial seizures, frontal lobe epilepsy, intracranial EEG monitoring, high-frequency oscillations, very high-frequency oscillations, HFOs, gamma mapping, direct electrical cortical stimulation, transcranial electrical stimulation, seizure onset, neocortical epilepsy, epilepsy and movement disorders, neurology, epileptic focus, BCI ethics, AI ethics.